

Bildnachweis: AdobeStock_240395963.
Synthetische klinische Studien sind neue statistische Verfahren zur Vorhersage der klinischen Wirkung einer Behandlung, die durch einen genetischen Proxy in Beobachtungsdaten aus Biobanken definiert und getestet wird. Synthetische klinische Studien haben das Potenzial, die Medikamentenentwicklung grundlegend zu verändern, wie die derzeitige Entwicklung eines COVID-19-Medikaments zeigt.
Die Zahl der Neuzulassungen von Medikamenten stagniert seit mehreren Jahren trotz steigender kommerzieller F&E-Ausgaben für Arzneimittel (Scannell et al. 2012). Infolgedessen ist die Kapitalrendite von Pharmaunternehmen von 10,1% im Jahr 2010 auf 3,2% anno 2017 gesunken. Die hohen Forschungs- und Entwicklungskosten und die sinkende Rendite der Arzneimittelentwicklung stellen gesellschaftlich die Gefahr dar, dass weniger in Medikamentenentwicklung investiert wird.
Studien über gescheiterte klinische Studien aus den Jahren 2012 bis 2015 zeigten, dass die höchsten Misserfolgsquoten von bis zu 75% in Phase II auftreten, in der die Wirksamkeit zum ersten Mal getestet wird (Harrison 2016). Die mangelnde Vorhersage der klinischen Wirkung eines neuen Medikaments ist das zentrale Risiko der pharmazeutischen Industrie.
Die Lücke zwischen Laborergebnissen und klinischer Wirksamkeit kann mittlerweile geschlossen werden, da bekannt ist, dass krankheitsassoziierte Gene zur Vorhersage der Wirksamkeit von Arzneimittelzielen verwendet werden können (Plenge et al. 2013). Retrospektive Analysen erfolgreicher und gescheiterter Arzneimittelentwicklungen haben gezeigt, dass Arzneimittelkandidaten, die an Wirkstoffziele binden, die genetisch mit der Krankheit verbunden sind, eine zwei- bis dreifach höhere Erfolgsquote in klinischen Studien aufweisen (Nelson et al. 2015; King et al.).
Mendelsche Randomisierung
Auf der Grundlage dieses Konzepts der genetischen Verknüpfung hat sich in den letzten Jahren die Mendelsche Randomisierung (MR) in der Wirkstoffentwicklung etabliert. Ähnlich wie in einer randomisierten klinischen Studie („randomized clinical trial“; RCT) gibt es eine Fall- und eine Kontrollgruppe, wobei die Randomisierung – wie der Name sagt – durch die Mendelschen Regeln in der Population erfolgt. Mithilfe der sogenannten Instrumentvariablenmethode kann der kausale Effekt von Genen für ein Merkmal (Exposure) auf eine Krankheit (Outcome) abgeschätzt werden. Bekanntestes Beispiel hierfür ist der kausale Effekt der Gene für erhöhtes LDL-Cholesterol auf Herz-Kreislauf-Erkrankungen.
Nichtsdestoweniger ist die Mendelsche Randomisierung dadurch limitiert, dass eine genügend große Schnittmenge an genetischen Varianten aus genomweiten Assoziationsstudien (GWAS) jeweils für das Merkmal (Exposure) sowie für die Krankheit (Outcome) statistisch signifikant ist. Bei zu geringer Anzahl kann die Instrumentenvariablenmethode nicht angewendet werden.
Synthetische klinische Studie
Der Begriff „synthetische klinische Studie“ wurde 2019 erstmals von Dr. Marjorie G. Zauderer erwähnt, als man aus elektronischen medizinischen Aufzeichnungen retrospektiv eine Fall- und eine Kontrollgruppe extrahierte, um die Wirkung eines Lungenkrebsmedikaments zu bestimmen (Zauderer et al. 2019). Konzeptionell unterscheidet sich die synthetische klinische Studie von der Mendelschen Randomisierung dadurch, dass aus Beobachtungsdaten Fall- und Kontrollgruppen definiert und extrahiert werden müssen, während bei der Mendelschen Randomisierung die Aufteilung der Natur bzw. den Mendelschen Regeln überlassen wird. Die synthetische klinische Studie ist daher die konsequente Weiterentwicklung der synthetischen Kontrollgruppe. Insbesondere in der Onkologie ist es unethisch, Patienten in einer randomisierten klinischen Studie einem Placebo auszusetzen – daher definiert man anhand von bereits bestehenden Daten eine synthetische Kontrollgruppe und testet den durchschnittlich erwartbaren Krankheitsverlauf gegen Probanden, die das Medikament bekommen.
Kausale Inferenz
Grundlage für die Mendelsche Randomisierung, synthetische klinische Studien und synthetische Kontrollgruppen sind statistische Verfahren, die die Reaktion der Effektvariablen analysieren, wenn eine Ursache der Effektvariablen geändert wird. Dies wird als kausale Inferenz bezeichnet und wurde vornehmlich in
den Wirtschaftswissenschaften entwickelt (Cunningham 2018). Im letzten Jahr wurden Joshua Angrist und Guido Imbens für ihre methodischen Beiträge zur kausalen Inferenz mit dem Nobelpreis für Wirtschaftswissenschaften ausgezeichnet.
Beispiel COVID-19
Bei biotx.ai haben wir anhand von Daten der UK Biobank nach signifikanten Unterschieden in 33 Blutzelltypen, 30 biochemischen Merkmalen des Blutes sowie dem Body-Mass-Index zwischen dem Phänotyp Lungenversagen durch eine Infektionskrankheit und gesunden Kontrollen gesucht (Baukmann et al.). Anschließend verglichen wir schwerkranke COVID-19-
Fälle mit Kontrollen, die nach einer SARS-CoV-2-Infektion leichte oder gar keine Symptome aufwiesen.
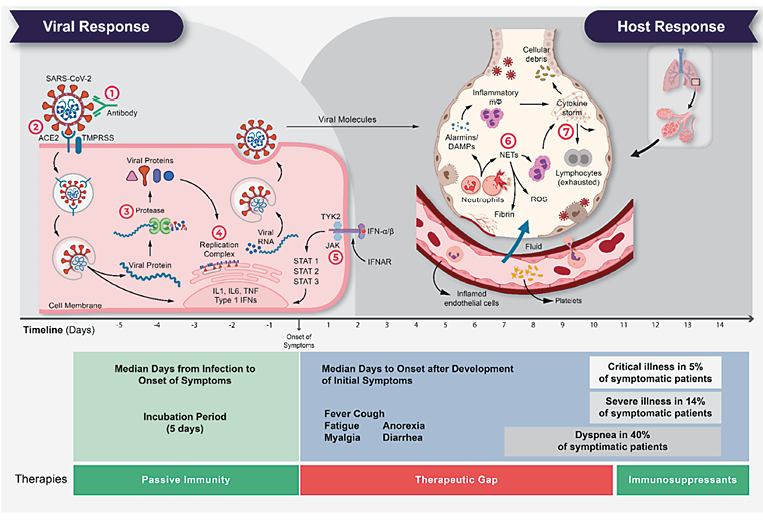
Mit diesen Daten erstellten wir eine synthetische klinische Studie, mit der wir eine hohe Anzahl neutrophiler Zellen und eine hohe Konzentration von Triglyceriden im Blut einhergehend mit einer Überreaktion des Immunsystems bei kritischen Erkrankungen aufgrund von COVID-19 nachweisen konnten. Auf Grundlage dieser Erkenntnisse identifizierten wir das Enzym CDK6 als potenzielles Arzneimittelziel zur Verhinderung einer Überreaktion des Immunsystems bei kritischen Erkrankungen aufgrund von COVID-19 bei Hochrisikopatienten mit hoher Neutrophilenzahl. Drei bestehende CDK6-Inhibitoren – Abemaciclib, Ribociclib und Palbociclib – sind für die Behandlung von Brustkrebs zugelassen.
CDK6 ist ein besonders attraktives Ziel für Medikamente, da es sich um ein menschliches Protein handelt und Mutationen des Virus die Wirkung des Medikaments somit nicht beeinflussen – ganz im Gegensatz zu antiviralen Medikamenten. Letztendlich könnten CDK6-Inhibitoren zu sogenannten „magic bullets“ werden, da sie gegen alle virusbedingten Immunpathologien eingesetzt werden und somit auch künftige Pandemien neuartiger Viren eindämmen könnten. Derzeitige klinische Untersuchungen werden zeigen, ob hohe Neutrophilenzahlen ursächlich für die kritische Erkrankung bei COVID-19 sind und ob somit deren Verringerung mit CDK6-Hemmern eine therapeutische Option darstellt.
Ausblick
Synthetische klinische Studien werden zwar mittelfristig nicht die bisherigen, langwierigen und teuren klinischen Studien ersetzen können – diese wohl aber massiv beschleunigen und das Risiko der Wirkstoffentwicklung deutlich zu vermindern imstande sein.
Die bisherige Medikamentenentwicklung basiert auf Hypothesen, die langwierig getestet werden müssen und daher nicht so skalierbar sind, wie wir es aus der Digitalwirtschaft kennen. Die Möglichkeit, durch Verfahren der kausalen Inferenz die Wirkung aus Biobankdaten abzuleiten, verändert die pharmazeutische Industrie derzeit auf radikale Weise. Wir sehen eine Transformation von der chemisch-pharmazeutischen Fabrik zum digitalen Datenunternehmen. So wurden in den vergangenen Jahren Hunderte von Start-ups im Bereich künstlicher Intelligenz in der Medikamentenentwicklung gegründet. Nicht alle diese Start-ups werden sich bewähren können, aber einige werden die pharmazeutische Industrie nachhaltig verändern.
Zum Person

Marco Schmidt ist Biochemiker und Mitgründer der biotx.ai GmbH, welche synthetische klinische Studien erstellt. Zuvor arbeitete er an der University of Cambridge UK für die EU-Kommission und für die Bill & Melinda Gates Foundation.
Dieser Beitrag erscheint in der Ausgabe „Smarte Medizin“ der Plattform Life Sciences 1/22.